Parts of Speech Tagging N-Grams
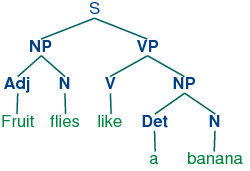 Part of my thesis is to analyze a set of SMS messages using Parts of Speech Tagging. I wanted to see what POS would come up with given SMS messages to analyze. It was interesting. For the most part POS could successfully tag each of the SMS messages properly but was curious to see if there was a higher rate of a specific noun/verb/pronoun/etc usage in SMS messages. This post isnt about the outcome but rather a forum to place the POS N-grams out.
Part of my thesis is to analyze a set of SMS messages using Parts of Speech Tagging. I wanted to see what POS would come up with given SMS messages to analyze. It was interesting. For the most part POS could successfully tag each of the SMS messages properly but was curious to see if there was a higher rate of a specific noun/verb/pronoun/etc usage in SMS messages. This post isnt about the outcome but rather a forum to place the POS N-grams out.
Some background
Before I could do anything I wanted to see if someone had already done this. I wanted to answer, Are there any N-grams for parts of speech tagging specifically for SMS text? Turns out I was either not looking in the correct place or there are non. So, I decided to create my own using the SMS data set located here: http://wing.comp.nus.edu.sg:8080/SMSCorpus/data/corpus/smsCorpus_en_xml_2012.04.30.zip
Creating the POS n-grams.
To create the POS n-grams I used the Treebank created by TweetNLP and then ran the output through some formatting of my own.
The files!
I now present you 2-gram, 3-gram, and 4-gram files based off of the SMS messages.
Download – 2 Gram
Download – 3 Gram
Download – 4 Gram
Armando Padilla

Intro – Research Section
Word Predicting in a Character Length restricted setting using PCFG