The Architecture
I started off by drawing plans on how to architect the Text Processor Engine (TPE) and realized I had to take several steps back and understand how the system as a whole would work. In the middle of that exercise I realized the TPE would not scale and wasn’t a very good path forward. I had to Pivot.
With that said, what is the arch? Look below 🙂
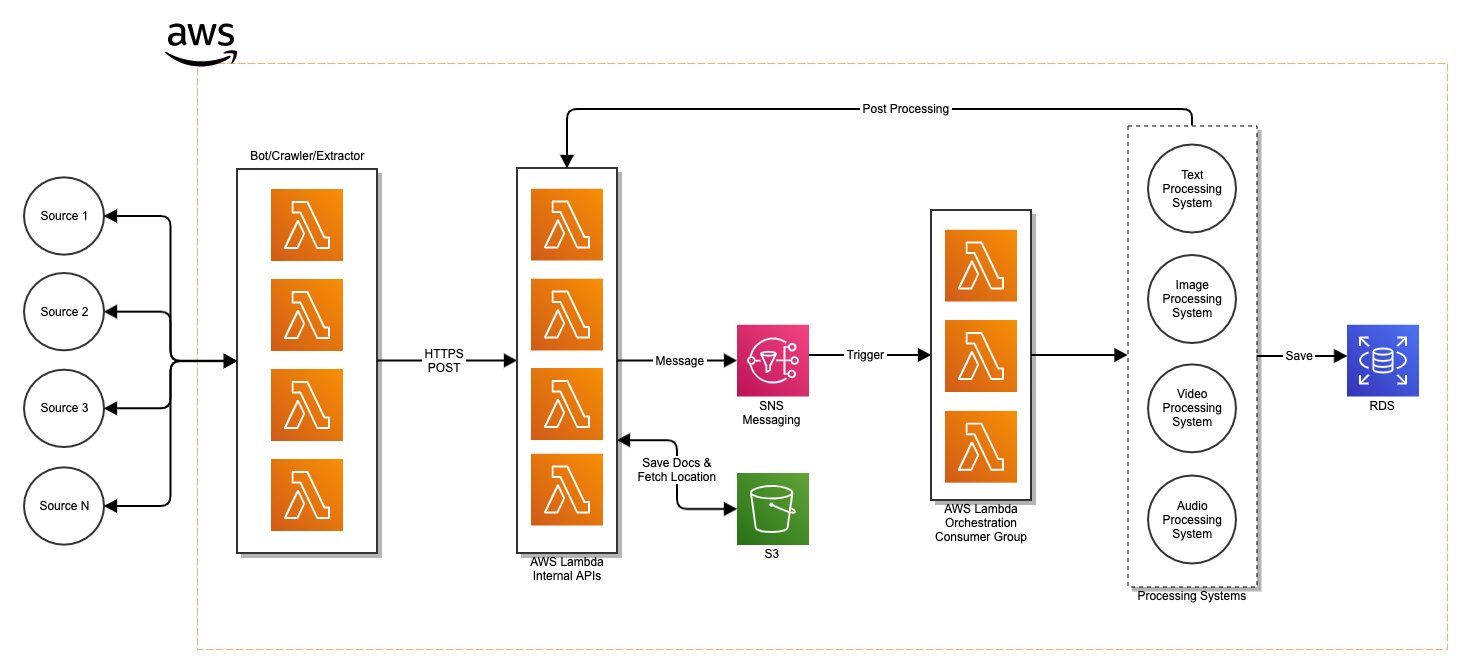
At a high level
I am not integrating the bots/crawlers/extractors directly into the processing system any longer. That was the flaw. I originally thought the source extraction layer (the first rectangle within the AWS ecosystem) would simply feed into the Processing System Rectangle (last rectangle in the AWS ecosystem). That wouldn’t work, it would but it wasnt optimal.
Because
- I didn’t want to become vendor locked. I didn’t want to update every N+1 bot/crawler/extractor if I decide AWS was not my preferred vendor/tech-solution moving forward.
- I also knew the Processing Systems would not respond with a valid response fast enough, thereby having the Source Extractor wait up to 5 minutes for a response. That wasnt/isnt ideal.
Source Extractor Layer – Layer 1
Starting with the first rectangle in the AWS ecosystem, Layer 1, I have the bots/crawlers/source-extractors fetching data from data sources as discussed before. Facebook, Instagram, etc etc. This layer is using NodeJS, running on AWS Lambda, and triggered by a Scheduled Event which runs every hour. Once the data is extracted it uses Layer 2, the Internal API.
Internal Thin API – Layer 2
The second layer in the overall system is the Internal Thin API. This thin layer api uses NodeJS, is strictly REST based, and runs on AWS Lambda. It will support only POST calls. Meaning, only creation of data will be allowed for now. No GET will be supported.
The API wont do any processing of the data it will simply consume the information supplied by the Source Extractor and pass it along to the next layer as a message. Again, optimizing for response time and execution time of the AWS Lambda, as well as making sure that at each layer I don’t become vendor locked.
Moving on, as mentioned above, the API layer will construct a message. The format of the message is a JSON as follows:
{
"Type": Type of media
"Input": Raw Data
"Source": "S3 Bucket Location - Video, Audio, Image"
"Date": Current Date.
"Processor": What Processor should kick off.
}I chose JSON vs Parquet or Avro because, no real reason. I do see changing this at some point but not now.
The above message will then be sent to Layer 3.
Messaging – Layer 3
The third layer is our messaging system and will use SNS. I could substitute this with SQS, RabbitMQ, Kafka, Kinesis, etc. but im sticking with SNS for now.
From a scaling point of view, it allows me to reduce the response time from the APIs to the source extractors by sending a message to this layer and responding quickly. Fire-and-Forget. For example, if the text api calls the text processing engine, and the text processing engine takes 5 minute to respond, that’s 5 minute the API will wait for a response to then give the OK to the callee. Using a messaging system, we can at least inform the callee that the request was placed into the next step, in this case the messaging queue, properly within seconds.
Once the message is placed into this layer, the Orchestration Layer is triggered.
The Orchestration Layer – Layer 4
The orchestration layer will orchestrate which processing system should take the message and consume it based on the “Processor” property in the JSON message. The text processing system, image processing system, or X.
This layer is triggered by a AWS Trigger, when the message lands within the Layer 3 SNS topic, which then stars up a AWS Lambda function. It then sends the message to the right Processing System.
For example, the below message will be sent to the Text Processing Engine. That Engine will then process the Input, “Hi mom, I miss you and love you”.
{
"Type": "text",
"Input": "Hi mom, I miss you and love you",
"Source": "",
"Date": July 9th, 2021 10:30pm
"Processor": "text"
}Processing Engines – Layer 5
The Processing Engines are different systems that deal with processing the different types of media. Theres the TPE, Video Processing Engine (VPE), Audio Processing Engine (APE), and Image Processing Engine (IPE). These system will be covered later in another post.
At a high level though, Once the engine runs through its black box of things to do it sends it to the DB or send the processed data back into the pipeline. What do I mean?
Let’s take an example of a video. The video, from the systems point of view, and mine, has 2 things. Video and Audio. The Video will be analyzed and the extracted info will be placed into the DB. The audio on the other hand needs to be analyzed so it will be placed into the messaging queue with a Processor of “audio”.
Once the Audio Processing engine extracts any text, that too will need to be analyzed. So the Audio processor will send a message into the system with message.processor = "text". The Text Processing Engine will then analyze and store the data into the DB and end the analysis of the incoming video.
Final thoughts
Vendor lock. Its not that I don’t think AWS is my solution its that I don’t know what 5-10 years down the road will look like. Maybe there is a better approach then, maybe there is an algorithm not within the AWS ecosystem that is doing Audio to Text extraction better. I don’t know, and thats why I honed in to that risk when designing this.
Semantic Graph / Knowledge Graphs. Doing some reading on Semantic Graphs. Semantic…..keeps following me around.
Armando Padilla


